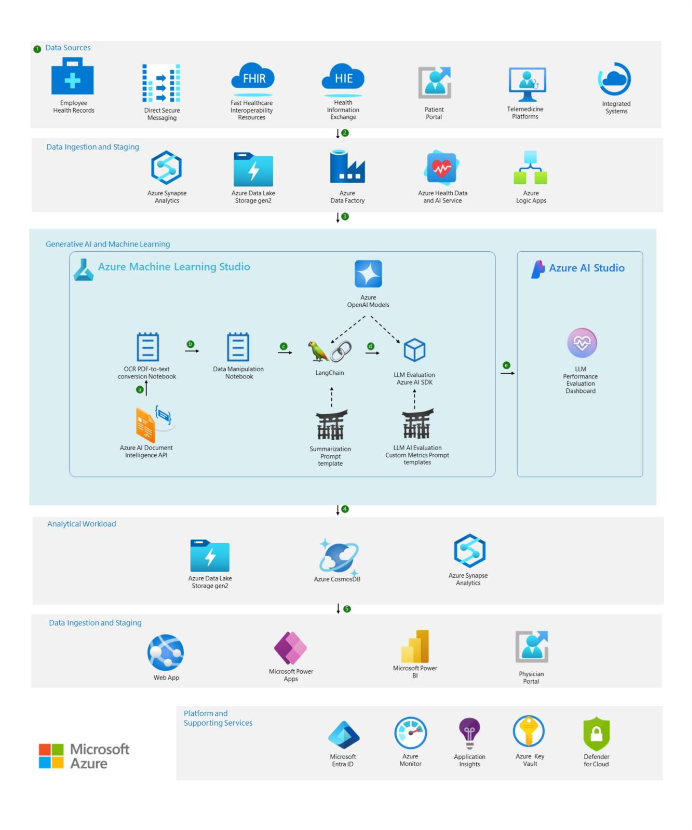
High-performance storage for AI Model Training tasks using Azure ML studio with Azure NetApp Files
Published Friday, August 26, 2022

Table of Contents
Provision persistent storage in Azure Machine Learning studio with Azure NetApp Files
Preparing the working environment
Azure Cloud Shell and Extensions
Creating Azure Machine Learning studio resources
Deployment steps - Azure Machine Learning studio notebooks
Accessing Azure NetApp Files from notebook
Creating a Snapshot using the Azure Cloud Shell
Restoring a snapshot using the Azure Cloud Shell
Abstract
This article describes how to create a notebook service in Azure Machine learning studio with attached attached persistent volume claim (PVC) on Azure NetApp Files volumes, the user can take advantage of the data protection features which come with Azure NetApp Files (ANF). The integration helps the data scientists quickly create clones of datasets that they can reformat, normalize, and manipulate while preserving the original “gold-source” dataset.
In this article you learn:
- How to create an Azure Machine learning studio
- How to create an Azure NetApp Files account, capacity pool, and delegated subnet
- How to provision an Azure NetApp Files NFS volume and connect it to an Azure Machine Learning notebook instance
Co-authors: Max Amende, Prabu Arjunan (NetApp)
Introduction
The Azure Machine Learning studio is the web portal for data scientist developers in Azure Machine Learning. The studio combines no-code and code-first experiences for an inclusive data science platform. Azure NetApp Files is an enterprise-class, high-performance, metered file storage service. You can select service and performance levels, create NetApp accounts, capacity pools, volumes, and manage data protection. Azure NetApp Files supports many workload types and is highly available by design.
The integration of the Azure Machine Learning studio with Azure NetApp Files is possible in several ways. In this article we'll cover two scenarios. One is provisioning the Azure NetApp Files for Azure Machine Learning notebooks, and the second is high-performance storage for AI model training tasks. By provisioning the Azure NetApp Files volumes to the Machine Learning notebooks, Azure NetApp Files provides persistency and data protection to the data.
Scenario
Data scientists face several challenges today; one is that data scientists cannot create a space-efficient data volume that’s an exact copy of an existing volume. By creating a Jupyter notebook or using as high-performance storage for AI Model Training tasks in Azure Machine learning studio with attached PVC on Azure NetApp Files volumes, the user can take advantage of the data protection features which come with Azure NetApp Files. The integration helps the data scientists quickly create clones of datasets that they can reformat, normalize, and manipulate while preserving the original “gold-source” dataset.
Provision persistent storage in Azure Machine Learning studio with Azure NetApp Files
Pre-requisites
- Microsoft Azure credentials that provide the necessary permissions to create the resources. In this example, we use use a user account with Contributor role. In the Preparing the working environment section of this document, we go over the required steps.
- An Azure Region where Azure NetApp Files is available
- Ability to provision the minimum Azure NetApp Files capacity pool
Note on Connectivity
The most important part of this process is ensuring connectivity between Azure Machine Learning studio and Azure NetApp Files. For this guide we will initialize the Azure Machine Learning studio compute instances and Azure NetApp Files volumes into the same Azure Virtual Network (VNet), while separating them into two different subnets (Azure NetApp Files requires a delegated subnet).
Preparing the working environment
In this guide we will deploy, configure, and connect Azure Machine Learning studio and Azure NetApp Files using the Azure Cloud Shell and a script hosted at:

https://github.com/prabuarjunan/anf-with-azureml
Alternatively, you could execute these steps using the Azure GUI.
Azure Cloud Shell and Extensions
Login to the Microsoft Azure Web-interface and open the Cloud Shell.

Then login into the Cloud Shell by entering:
user@Azure:~$ az login
Cloud Shell is automatically authenticated under the initial account signed-in with. Run 'az login' only if you need to use a different account
To sign in, use a web browser to open the page https://microsoft.com/devicelogin and enter the code “Secure Code” to authenticate.
To provision Azure NetApp Files and Azure Machine Learning from the Cloud Shell we need to install the following CLI extensions:
user@Azure:~$ az extension add --name ml
user@Azure:~$ az provider register --namespace Microsoft.NetApp --wait
Setting variables
# Resource group name
rg='aml-anf-test'
location='westeurope'
# VNET details
vnet_name='vnet'
vnet_address_range='10.0.0.0/16'
vnet_aml_subnet='10.0.1.0/24'
vnet_anf_subnet='10.0.2.0/24'
# AML details
workspace_name='aml-anf'
# ANF details
anf_name=anf
pool_name=pool1
You can modify these variables so that they fit your deployment. As stated in the Note on Connectivity section, it is important that the Azure Machine Learning studio and Azure NetApp Files subnets are part of the same VNet. Ensure the “location” selected supports Azure NetApp Files.
For this document we stick with these variables. In case the Cloud Shell times-out, or you shut it down in between the following steps, the variables have to be reinitialized.
Deployment steps:
Provisioning of services
After we initialize the variables, we need to provision the required services and network. First, we create our resource group and define the defaults for the working environment:
user@Azure:~$ az group create -n $rg -l $location
{
"id": "/subscriptions/number/resourceGroups/aml-anf-test",
"location": "westeurope",
"managedBy": null,
"name": "aml-anf-test",
"properties": {
"provisioningState": "Succeeded"
},
"tags": null,
"type": "Microsoft.Resources/resourceGroups"
}
user@Azure:~$ az configure --defaults group=$rg workspace=$workspace_name location=$location
Followed by the VNet and subnets:
user@Azure:~$ az network vnet create -n $vnet_name --address-prefix $vnet_address_range
{
"newVNet": {
"addressSpace": {
"addressPrefixes": [
"10.0.0.0/16"
]
},
...
}
}
user@Azure:~$ {
"addressPrefix": "10.0.1.0/24",
"addressPrefixes": null,
"applicationGatewayIpConfigurations": null,
...
}
user@Azure:~$ az network vnet subnet create --vnet-name $vnet_name -n anf --address-prefixes $vnet_anf_subnet --delegations "Microsoft.NetApp/volumes"
{
"addressPrefix": "10.0.2.0/24",
"addressPrefixes": null,
"applicationGatewayIpConfigurations": null,
"delegations": [
{
"actions": [
"Microsoft.Network/networkinterfaces/*",
"Microsoft.Network/virtualNetworks/subnets/join/action"
],
"etag": "W/\"number\"",
"id": "/subscriptions/number/resourceGroups/aml-anf-test/providers/Microsoft.Network/virtualNetworks/vnet/subnets/anf/delegations/0",
"name": "0",
"provisioningState": "Succeeded",
"resourceGroup": "aml-anf-test",
"serviceName": "Microsoft.NetApp/volumes",
"type": "Microsoft.Network/virtualNetworks/subnets/delegations"
}
],
...
}
We reduced the output of certain fields indicated by “…” for readability.
|
(!) Note
The Azure NetApp Files subnet has to be separate from the Azure Machine Learning studio subnet and be explicitly delegated to Azure NetApp Files. |
Next, we are going to provision the Azure Machine Learning workspace:
user@Azure:~$ az ml workspace create --name $workspace_name
The deployment request aml-anf-47652685 was accepted. ARM deployment URI for reference:
https://portal.azure.com//#blade/HubsExtension/DeploymentDetailsBlade/overview/id/%2Fsubscriptions%number%2FresourceGroups%2Faml-anf-test%2Fproviders%2FMicrosoft.Resources%2Fdeployments%2Faml-anf-476562285
Creating AppInsights: (amlanfinsights80221d528b9e ) Done (7s)
Creating KeyVault: (amlanfkeyvault01027221d033 ) .. Done (23s)
Creating Storage Account: (amlanfstoragecad13288ba5c ) Done (27s)
Creating workspace: (aml-anf ) .. Done (16s)
Total time : 45s
{
"application_insights": "/subscriptions/number/resourceGroups/aml-anf-test/providers/Microsoft.insights/components/amlanfinsights82021d58b9e",
"description": "aml-anf",
"discovery_url": "https://westeurope.api.azureml.ms/discovery",
"display_name": "aml-anf",
"hbi_workspace": false,
"id": "/subscriptions/number/resourceGroups/aml-anf-test/providers/Microsoft.MachineLearningServices/workspaces/aml-anf",
"key_vault": "/subscriptions/number/resourceGroups/aml-anf-test/providers/Microsoft.Keyvault/vaults/amlanfkeyvault0102712d033",
"location": "westeurope",
"mlflow_tracking_uri": "azureml://westeurope.api.azureml.ms/mlflow/v1.0/subscriptions/number/resourceGroups/aml-anf-test/providers/Microsoft.MachineLearningServices/workspaces/aml-anf",
"name": "aml-anf",
"public_network_access": "Enabled",
"resourceGroup": "aml-anf-test",
"resource_group": "aml-anf-test",
"storage_account": "/subscriptions/number/resourceGroups/aml-anf-test/providers/Microsoft.Storage/storageAccounts/amlanfstoragecad132828ba5c",
"tags": {
"createdByToolkit": "cli-v2-2.6.1"
}
}
We are going to create an NetApp account, a capacity pool, and a volume:
user@Azure:~$ az netappfiles account create --name $anf_name
{
"activeDirectories": null,
"encryption": {
"keySource": "Microsoft.NetApp"
},
"etag": "W/\"datetime'2022-07-28T13%3A23%3A20.5825376Z'\"",
"id": "/subscriptions/number/resourceGroups/aml-anf-test/providers/Microsoft.NetApp/netAppAccounts/anf",
"location": "westeurope",
"name": "anf",
"provisioningState": "Succeeded",
"resourceGroup": "aml-anf-test",
"systemData": {
"createdAt": "2022-07-28T13:23:20.358899+00:00",
"createdBy": "[email protected]",
"createdByType": "User",
"lastModifiedAt": "2022-07-28T13:23:20.358899+00:00",
"lastModifiedBy": "[email protected]",
"lastModifiedByType": "User"
},
"tags": null,
"type": "Microsoft.NetApp/netAppAccounts"
}
user@Azure:~$ az netappfiles pool create --account-name $anf_name --name $pool_name --size 4 --service-level premium
{
"coolAccess": false,
"encryptionType": "Single",
"etag": "W/\"datetime'2022-07-28T13%3A23%3A52.6524588Z'\"",
"id": "/subscriptions/number/resourceGroups/aml-anf-test/providers/Microsoft.NetApp/netAppAccounts/anf/capacityPools/pool1",
"location": "westeurope",
"name": "anf/pool1",
"poolId": "number",
"provisioningState": "Succeeded",
"qosType": "Auto",
"resourceGroup": "aml-anf-test",
"serviceLevel": "Premium",
"size": 4398046511104,
"systemData": null,
"tags": null,
"totalThroughputMibps": 256.0,
"type": "Microsoft.NetApp/netAppAccounts/capacityPools",
"utilizedThroughputMibps": 0.0
}
user@Azure:~$ az netappfiles volume create --account-name $anf_name --pool-name $pool_name --name vol1 --service-level premium --usage-threshold 4096 --file-path "vol1" --vnet $vnet_name --subnet anf --protocol-types NFSv3 --allowed-clients $vnet_aml_subnet --rule-index 1 --unix-read-write true
{
"avsDataStore": "Disabled",
"backupId": null,
"baremetalTenantId": "baremetalTenant_svm_47702141844c3d28e8de7c602a040a58_e7f3a9a9",
"capacityPoolResourceId": null,
"cloneProgress": null,
"coolAccess": false,
"coolnessPeriod": null,
"creationToken": "vol1",
...
}
We reduced the output of certain fields indicated by “…” for readability.
|
(!) Note |
We are using NFSv3 as a protocol for this example, but NFSv4.1 should work as well.
Preparing repository
To access the prepared YAML files, we are next downloading the repository and unzipping it:
user@Azure:~$ wget https://github.com/prabuarjunan/anf-with-azureml/archive/refs/heads/main.zip
--2022-07-28 13:44:46-- https://github.com/prabuarjunan/anf-with-azureml/archive/refs/heads/main.zip
Resolving github.com (github.com)... 140.82.121.4
Connecting to github.com (github.com)|140.82.121.4|:443... connected.
HTTP request sent, awaiting response... 302 Found
Location: https://codeload.github.com/prabuarjunan/anf-with-azureml/zip/refs/heads/main [following]
--2022-07-28 13:44:46-- https://codeload.github.com/prabuarjunan/anf-with-azureml/zip/refs/heads/main
Resolving codeload.github.com (codeload.github.com)... 140.82.121.10
Connecting to codeload.github.com (codeload.github.com)|140.82.121.10|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: unspecified [application/zip]
Saving to: ‘main.zip’
main.zip [ <=> ] 6.52K --.-KB/s in 0.002s
2022-07-28 13:44:46 (3.10 MB/s) - ‘main.zip’ saved [6681]
user@Azure:~$ unzip main.zip && rm main.zip
Archive: main.zip
d4833609633fea55011f705f1b00cb829b720388
creating: anf-with-azureml-main/
inflating: anf-with-azureml-main/.gitignore
inflating: anf-with-azureml-main/README.md
creating: anf-with-azureml-main/code/
inflating: anf-with-azureml-main/code/train.py
inflating: anf-with-azureml-main/environment.yml
creating: anf-with-azureml-main/environment/
inflating: anf-with-azureml-main/environment/Dockerfile
inflating: anf-with-azureml-main/environment/requirements.txt
inflating: anf-with-azureml-main/train.yml
user@Azure:~$ cd anf-with-azureml-main
Creating Azure Machine Learning studio resources
We execute the environment YAML to create an Azure Machine Learning environment:
user@Azure:~/anf-with-azureml-main$ az ml environment create --file environment.yml
Uploading environment (0.0 MBs): 100%|| 578/578 [00:00<00:00, 5050641.07it/s]
{
"build": {
"dockerfile_path": "Dockerfile",
"path": "https://amlanfstoragecad1388ba5c.blob.core.windows.net/azureml-blobstore/LocalUpload/number/environment/"
},
"creation_context": {
"created_at": "2022-07-28T13:46:51.238036+00:00",
"created_by": "user",
"created_by_type": "User",
"last_modified_at": "2022-07-28T13:46:51.238036+00:00",
"last_modified_by": "user",
"last_modified_by_type": "User"
},
"description": "Environment with NFS drivers and a few Python libraries.",
"id": "azureml:/subscriptions/user/resourceGroups/aml-anf-test/providers/Microsoft.MachineLearningServices/workspaces/aml-anf/environments/python-base-nfs/versions/1",
"name": "python-base-nfs",
"os_type": "linux",
"resourceGroup": "aml-anf-test",
"tags": {},
"version": "1"
}
The environment.yml uses one of the default Azure Machine Learning Docker files as its base and adds NFS functionality and some Python libraries.
Based on the newly created Docker file, we spin up an Azure Machine Learning compute cluster:
user@Azure:~/anf-with-azureml-main$ az ml compute create -n cpu-cluster --type amlcompute --min-instances 0 --max-instances 1 --size Standard_F16s_v2 --vnet-name $vnet_name --subnet aml --idle-time-before-scale-down 1800
{
"id": "/subscriptions/number/resourceGroups/aml-anf-test/providers/Microsoft.MachineLearningServices/workspaces/aml-anf/computes/cpu-cluster",
"idle_time_before_scale_down": 1800,
"location": "westeurope",
"max_instances": 1,
"min_instances": 0,
"name": "cpu-cluster",
"network_settings": {
"subnet": "/subscriptions/number/resourceGroups/aml-anf-test/providers/Microsoft.Network/virtualNetworks/vnet/subnets/aml"
},
"provisioning_state": "Succeeded",
"resourceGroup": "aml-anf-test",
"size": "STANDARD_F16S_V2",
"ssh_public_access_enabled": false,
"tier": "dedicated",
"type": "amlcompute"
}
Start training job
As soon as the cluster is ready, we can schedule our first job, which accesses the Azure NetApp Files volume:
user@Azure:~/anf-with-azureml-main$ az ml job create -f train.yml --web
Uploading code (0.0 MBs): 100%|| 134/134 [00:00<00:00, 19167.75it/s]
{
"code": "azureml:/subscriptions/number/resourceGroups/aml-anf-test/providers/Microsoft.MachineLearningServices/workspaces/aml-anf/codes/number/versions/1",
"command": "mkdir /data\nmount -t nfs -o rw,hard,rsize=65536,wsize=65536,vers=3,tcp 10.0.2.4:/vol1 /data\ndf -h\npython train.py\n# Run fio on NFS share\ncd /data\nfio --name=4krandomreads --rw=randread --direct=1 --ioengine=libaio --bs=4k --numjobs=4 --iodepth=128 --size=1G --runtime=60 --group_reporting\n# Run fio on local disk\nmkdir /test\ncd /test\nfio --name=4krandomreads --rw=randread --direct=1 --ioengine=libaio --bs=4k --numjobs=4 --iodepth=128 --size=1G --runtime=60 --group_reporting\n",
"compute": "azureml:cpu-cluster",
"creation_context": {
"created_at": "2022-07-28T13:54:49.207835+00:00",
"created_by": "User",
"created_by_type": "User"
},
"display_name": "joyful_arm_nmt86c42pqw",
"environment": "azureml:python-base-nfs:1",
"environment_variables": {},
"experiment_name": "anf-with-azureml-main",
"id": "azureml:/subscriptions/number/resourceGroups/aml-anf-test/providers/Microsoft.MachineLearningServices/workspaces/aml-anf/jobs/joyful_arm_nmt86c4pqw",
"inputs": {},
"name": "joyful_arm_nmt86c24pqw",
"outputs": {
"default": {
"mode": "rw_mount",
"path": "azureml://datastores/workspaceartifactstore/ExperimentRun/dcid.joyful_arm_nmt86c4pqw",
"type": "uri_folder"
}
},
"parameters": {},
"properties": {
"ContentSnapshotId": "14d4962c4-7143-434f-bdb2-bd1a2278d0ced",
"_azureml.ComputeTargetType": "amlctrain"
},
"resourceGroup": "aml-anf-test",
"resources": {
"instance_count": 1,
"properties": {}
},
"services": {
"Studio": {
"endpoint": "https://ml.azure.com/runs/joyful_arm_nmt86c4pqw?wsid=/subscriptions/number/resourcegroups/aml-anf-test/workspaces/aml-anf&tid=4b09112a0-929b-4715-944b-c037425165b3a",
"job_service_type": "Studio"
},
"Tracking": {
"endpoint": "azureml://westeurope.api.azureml.ms/mlflow/v1.0/subscriptions/number/resourceGroups/aml-anf-test/providers/Microsoft.MachineLearningServices/workspaces/aml-anf?",
"job_service_type": "Tracking"
}
},
"status": "Starting",
"tags": {},
"type": "command"
}
In case you receive the following error:
Failed to connect to MSI. Please make sure MSI is configured correctly.
Get Token request returned: <Response [400]>
One possible reason for the error is a problem with authentication. Try:
az login
When checking train.yml we see that with this job, we are running a storage benchmark, which compares the speed of the compute clusters’ integrated storage to the speed of the attached Azure NetApp Files volume:
$schema: https://azuremlschemas.azureedge.net/latest/commandJob.schema.json
compute: azureml:cpu-cluster
environment: azureml:python-base-nfs:1
code:
code/
command: |
mkdir /data
mount -t nfs -o rw,hard,rsize=65536,wsize=65536,vers=3,tcp 10.0.2.4:/vol1 /data
df -h
python train.py
# Run fio on NFS share
cd /data
fio --name=4krandomreads --rw=randread --direct=1 --ioengine=libaio --bs=4k --numjobs=4 --iodepth=128 --size=1G --runtime=60 --group_reporting
# Run fio on local disk
mkdir /test
cd /test
fio --name=4krandomreads --rw=randread --direct=1 --ioengine=libaio --bs=4k --numjobs=4 --iodepth=128 --size=1G --runtime=60 --group_reporting
In addition to the executed benchmark, a small Python script is being executed. In a real-world scenario, the Python script is the part which is of interest. For example, the Python script could contain the code to train for Natural Language Processing (NLP) or Object Detection model.
Results of training job
For this paper we are interested to show the speed difference between the two storage classes. To see the results, we return to the Azure GUI and navigate to the Azure Machine Learning view. There we'll see a workspace with our defined name. If you used the same resource names used in this guide, the name will be “amf-anf”.

Next, select this workspace and we'll see a screen like this one:

To see the results, we then proceed by clicking on the “Studio-Web-URL” on the right. After opening Azure Machine Learning studio we click on the left on “Jobs”. We now see all the jobs which we have run in the Azure Machine Learning studio.

Next, change the view from “All experiments” to “All jobs”. If you followed the document, there should be one job listed. Wait until the status of the job changes to “Completed”.

Then click on the job to get more information and options.

Next, select “Outputs + logs”, followed by a click on click on “user_logs”, and then select “std_log.txt” to see the results from the benchmark.

In the log you'll see that Azure NetApp Files is about twice as fast as the compute clusters’ integrated storage.
Deployment steps - Azure Machine Learning studio notebooks
An alternative use case for Azure NetApp Files and Azure Machine Learning studio, is to use Azure NetApp Files as a file storage for experiments using Azure Machine Learning studio notebooks.
While the majority of required steps are the same, there are some distinctive differences. In this section we will show you how to use Azure NetApp Files together with Azure Machine Learning studio notebooks.
Preparation and requirements
For preparing the environment, please follow the steps “Azure Cloud Shell and Extensions, Setting variables and Provisioning of services” from the earlier parts of the document. You can also execute this part of the guide, if you followed all previous steps and still have the compute cluster running. Just be aware in case you receive errors regarding the “Quota”, that you might have to shut down the previously deployed compute cluster (or modify your Quota).
Provisioning Compute instance
Open the Azure Machine Learning studio.
In case you have never accessed the Azure Machine Learning studio, follow the steps from Results of training job until the point where we access the results from the training job.
Click on “Compute”:

|
(!) Note
In case you followed all previous steps, you will see your previously provisioned compute cluster under “Compute clusters” |
Then select “+ New” (In the “Compute instances” tab, not in the “Compute clusters” tab).

Give the compute instance a name of your choice, we call it “ANFTestCompute” in this guide and select a Virtual Machine size. For this demo, the least expensive instance is sufficient.
|
(!) Important
Do not click on “Create” yet, but select “Next: Advanced Settings”. |

In the “Advanced Settings” tab, activate “Enable virtual network”, and select the VNet which we previously created. If you followed the guide, the VNet should be called “vnet (aml-anf-test)”.
Then select the subnet, which has not been delegated to Azure NetApp Files, in our case “aml”.
Now we can click on “Create”.
Provisioning the compute instance will take a couple of minutes. Wait until the “State” of the instance switched to “Running”

Configuring compute instance
In the “Compute instances” tab under “Applications”, click on the “Terminal” to connect to the Compute instance.
Next, we need to install nfs-common:
azureuser@anftestcompute:~/cloudfiles/code/Users/user$ sudo apt install nfs-common -y
Reading package lists... Done
Building dependency tree
Reading state information... Done
The following packages were automatically installed and are no longer required:
ca-certificates-java cmake-data cuda-command-line-tools-11-1
cuda-command-line-tools-11-3 cuda-compiler-11-1 cuda-compiler-11-3
cuda-cudart-11-1 cuda-cudart-11-3 cuda-cudart-dev-11-1 cuda-cudart-dev-11-3
cuda-cuobjdump-11-1 cuda-cuobjdump-11-3 cuda-cupti-11-1 cuda-cupti-11-3
cuda-cupti-dev-11-1 cuda-cupti-dev-11-3 cuda-cuxxfilt-11-3
cuda-documentation-11-1 cuda-documentation-11-3 cuda-driver-dev-11-1
…
We reduced the output of certain fields indicated by “…” for readability.
Next, create a new folder and mount the Azure NetApp Files volume.
azureuser@anftestcompute:~/cloudfiles/code/Users/user$ mkdir data
azureuser@anftestcompute:~/cloudfiles/code/Users/user$ sudo mount -t nfs -o rw,hard,rsize=65536,wsize=65536,vers=3,tcp 10.0.2.4:/vol1 /data
If you followed the instruction, your screen should look now, like that:

|
(!) Note
In case the “data” folder is not shown yet on the left side, click on the “Refresh” button. |
As an example, we are downloading the titanic dataset to the Azure NetApp Files volume. The titanic dataset established itself as the standard first data science project for emerging data scientists.
azureuser@anftestcompute:~$ wget https://web.stanford.edu/class/archive/cs/cs109/cs109.1166/stuff/titanic.csv -P ./data
--2022-07-29 13:55:56-- https://web.stanford.edu/class/archive/cs/cs109/cs109.1166/stuff/titanic.csv
Resolving web.stanford.edu (web.stanford.edu)... 171.67.215.200, 2607:f6d0:0:925a::ab43:d7c8
Connecting to web.stanford.edu (web.stanford.edu)|171.67.215.200|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 44225 (43K) [text/csv]
Saving to: ‘./data/titanic.csv’
titanic.csv 100%[==================================================================================================================================>] 43.19K 133KB/s in 0.3s
2022-07-29 13:56:00 (133 KB/s) - ‘./data/titanic.csv’ saved [44225/44225]
Accessing Azure NetApp Files from Notebook
Next, create a new Jupyter/ Azure Machine Learning studio Notebook. Therefore, we click on the “Plus Button” on the left.

And select “Create new file”.
For this document we call the Notebook “ANFNotebook”:

And then click on “Create”.
From the Notebook we can now access the files on the Azure NetApp Files volume and build our models based on it.

Snapshots
Because the NetApp DataOps Toolkit does not support Azure NetApp Files we are using Azure NetApp Files snapshots instead. Snapshots are a valuable tool for data science tasks.
Creating snapshots of Azure NetApp Files volumes is possible in many ways, like
- using the GUI,
- using the Azure Cloud Shell,
- the REST API,
- or directly out of Python.
For this document we will use the Azure Cloud Shell to create and restore a snapshots.
Creating a Snapshot using the Azure Cloud Shell
For creating a Snapshot, we first open the Azure Cloud Shell. Then we enter the following command:
user@Azure:~$ az netappfiles snapshot create --account-name anf --resource-group aml-anf-test --pool-name pool1 --volume-name vol1 --name timeInPointCopy
{
"created": "2022-08-01T15:35:25+00:00",
"etag": "8/1/2022 3:35:27 PM",
"id": "/subscriptions/number/resourceGroups/aml-anf-test/providers/Microsoft.NetApp/netAppAccounts/anf/capacityPools/pool1/volumes/vol1/snapshots/timeInPointCopy",
"location": "westeurope",
"name": "anf/pool1/vol1/timeInPointCopy",
"provisioningState": "Succeeded",
"resourceGroup": "aml-anf-test",
"snapshotId": "da003b7f-195d-2c1d-c192e-20472fa662c3d",
"type": "Microsoft.NetApp/netAppAccounts/capacityPools/volumes/snapshots"
}
The command requires you to specify the NetApp account name, the resource group, the capacity pool name, the name of the volume of which you want to create a snapshot, and a name for the snapshot.
|
(!) Note
For this section we used the variable names from Setting variables. |
Data scientists can use snapshots as an effective and space efficient way for versioning a data set.
Restoring a snapshot using the Azure Cloud Shell
When restoring a Snapshot, there are three options:
- Reverting a volume from snapshot
- Restoring a snapshot to a new volume
- Restoring single files from a snapshot
For this example we will choose the second option. This means a new volume with a new name will be created based on the selected snapshot, and the volume data will automatically be restored to this volume.
user@Azure:~$ az netappfiles volume create --vnet vnet1 --account-name anf --usage-threshold 100 --pool-name pool1 --resource-group aml-anf-test --snapshot-id da003b7f-195d-2c1d-c192e-20472fa662c3d --name vol1copy --file-path vol1copy --service-level premium --protocol-types NFSv3 --allowed-clients '10.0.1.0/24' --rule-index 1 --unix-read-write true
{
"avsDataStore": "Disabled",
"backupId": null,
"baremetalTenantId": "baremetalTenant_svm_47702141844c3d28e8de27c602a040a58_12a18d7cc",
"capacityPoolResourceId": null,
"cloneProgress": 0,
"coolAccess": false,
"coolnessPeriod": null,
... }
We reduced the output of certain fields indicated by “…” for readability.
|
(!) Note
Entering the command from above might be prone to errors, due to its length and the number of required details. This operation might be easier to conduct using the Azure GUI. |
The above example's volume creation is based on the snapshot Setting variables and Provisioning of services. Additionally, we need to specify the new volume's name, the mount point, and the snapshot id.
Summary
In this article we described how we can make Azure Machine Learning studio use enterprise-grade high performance persistent storage backed by Azure NetApp Files volumes for the compute instances. Get started with Azure NetApp Files today.
Additional Information
- https://azure.microsoft.com/services/machine-learning/
- https://kubernetes.io/docs/concepts/storage/persistent-volumes/
Continue to website...