How Putting CDN After Your Reverse Proxy Creates a Single Point of Failure
This is a universal architecture anti-pattern that affects teams across all cloud providers and technology stacks. Whether you are using nginx, HAProxy, Envoy or cloud load balancers, the problem is the same: placing a CDN after your reverse proxy instead of before it defeats the CDN’s distributed architecture.
Let us understand why this happens and why it is dangerous, regardless of your technology choices.
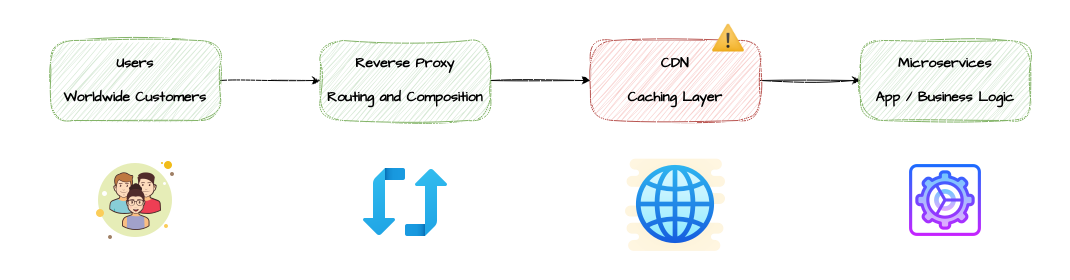
Why This Architecture Fails: The Fundamental Problem
-
Your reverse proxy operates from a limited IP address space : Even with auto-scaling, multi-zone deployment and load balancing, your reverse proxy cluster runs on a finite set of IP addresses within your data center or cloud VPC. These IPs are geographically concentrated.
# Example: nginx cluster with 10 nodes nginx-1: 10.0.1.5 nginx-2: 10.0.1.8 nginx-3: 10.0.2.12 ... nginx-10: 10.0.3.45 All IPs from the same /16 or /24 subnet All IPs in the same geographic region Even with 100 nodes, still limited IP space! -
CDN sees your entire proxy cluster as a single client location: CDNs route traffic based on source IP geolocation. When all requests originate from your proxy’s data center (even from multiple IPs), the CDN’s routing algorithm treats this as one geographic location requesting content.
# Normal (user-facing CDN) User in Tokyo → CDN routes to Tokyo PoP # This anti-pattern All traffic from proxy IPs (e.g. US-East) → CDN routes ALL to US-East PoP -
100% of your traffic flows through ONE CDN Point of Presence: Instead of distributing globally across hundreds of edge locations, all your traffic is routed to the single PoP nearest to your reverse proxy cluster.
# CORRECT: User-facing CDN Origin User in Tokyo → Tokyo PoP Origin User in London → London PoP Origin User in New York → Virginia PoP Origin User in Sydney → Sydney PoP Origin Result: Distributed across 4 PoPs ✅ # WRONG: CDN behind reverse proxy All Users → Reverse Proxy (US-East IPs) → Virginia PoP ONLY Backend Result: Single PoP = Single Point of Failure ❌ -
When that one PoP fails → 100% of users are impacted: Your carefully architected multi-zone reverse proxy becomes irrelevant. If the single CDN PoP experiences:
- Network congestion
- Hardware failure
- Software bug
- DDoS attack
- Maintenance downtime
ALL your users worldwide experience an outage
Why Teams Build This (By Accident)
- Organic evolution: Started with Users → Proxy → Backend, then added “caching” without understanding CDN routing
- Wrong mental model: Treating CDN as a cache layer (like Redis) instead of an edge network
- Legacy migration: Lifted-and-shifted on-prem architecture without redesign
- Quick fix that stuck: “Backend is slow, let us add caching here!” without proper architecture review
The Correct AWS Architectures
Now that we understand the problem, let us look at three correct ways to implement caching and content delivery in AWS. Each pattern solves specific use cases and eliminates the single point of failure.
ElastiCache for Internal Caching
Move caching inside your VPC using ElastiCache (Redis or Memcached). This provides distributed caching with true multi-AZ high availability, without any external routing layer to become a bottleneck.
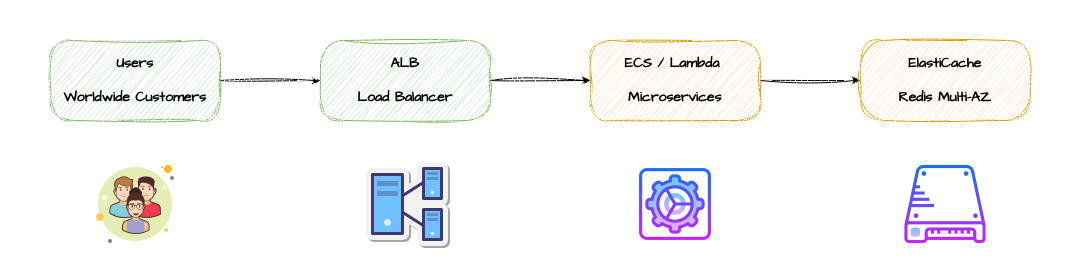
Why This Works:
- No external routing layer to become a bottleneck
- Sub-millisecond latency within VPC
- True multi-AZ high availability with automatic failover
- Fine-grained cache control in application code
- ElastiCache Cluster Mode for horizontal scaling
CloudFront in Front of ALB (User-Facing)
Place CloudFront where it belongs: directly facing users. This restores the CDN’s global distribution, provides DDoS protection, and delivers edge caching benefits without creating routing bottlenecks.
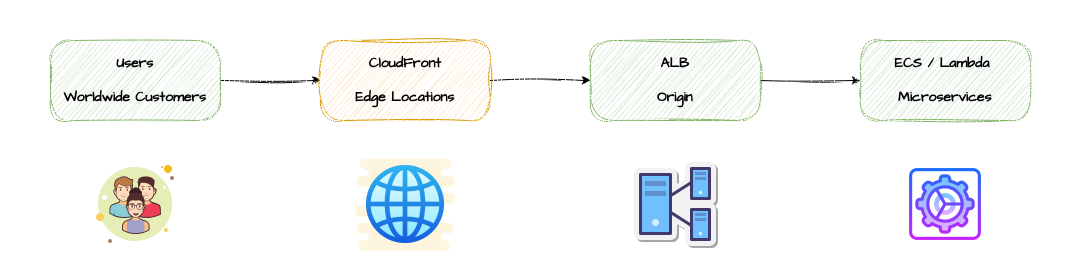
Why This Works:
- Users route to nearest CloudFront edge → low latency for all
- True global distribution across hundreds of locations
- Built-in DDoS protection with AWS Shield Standard
- SSL/TLS termination at edge reduces origin load
- No single point of failure in routing layer
- Cache static AND dynamic content at edge
Lambda@Edge for Edge Computing
Execute routing, A/B testing and composition logic at CloudFront edge locations using Lambda@Edge. This can eliminate the reverse proxy layer entirely for certain workloads.
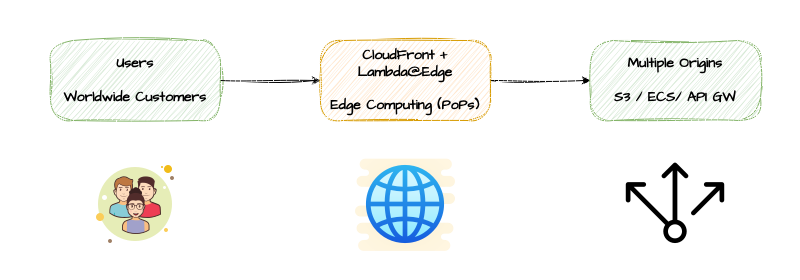
Why This Works:
- Logic executes at hundreds of edge locations (ultra-low latency)
- No centralized reverse proxy to become a bottleneck
- Dynamic routing, A/B testing, auth at edge
- Can eliminate ALB costs for some workloads
- Geo-based content delivery
- Request/response manipulation at edge
Quick Decision Guide
Choose ElastiCache when
- ✅ You need internal caching within your VPC
- ✅ Sub-millisecond latency is critical
- ✅ You want full control over cache logic
- ✅ Session management across microservices
- ✅ Database query result caching
- ❌ Do not need global distribution
Choose CloudFront + ALB when
- ✅ You have a global user base
- ✅ You need DDoS protection
- ✅ You serve static or semi-static content
- ✅ SSL/TLS termination at edge is desired
- ✅ Cost-effective solution needed
- ❌ Do not need complex edge logic
Choose Lambda@Edge when
- ✅ You need complex logic at the edge
- ✅ A/B testing or personalization required
- ✅ Geographic content routing needed
- ✅ Authentication/authorization at edge
- ✅ You want to eliminate ALB for some workloads
- ❌ Do not mind higher complexity
Common Objection: What About Multi-Region Proxy Clusters?
A common question arises: “If I deploy my proxy clusters in multiple regions (US-East, EU-West, AP-Southeast), doesn’t that solve the single point of failure problem?”
Short answer: It reduces the blast radius but does not eliminate the anti-pattern.
What Multi-Region Proxies Give You
# Multi-region proxy setup
US Users → US Proxy Cluster → CDN Virginia PoP → Backend
EU Users → EU Proxy Cluster → CDN London PoP → Backend
Asia Users → Asia Proxy Cluster → CDN Singapore PoP → Backend
At first glance, this seems better—you are no longer routing all traffic through a single CDN PoP. Each regional proxy cluster routes to its nearest CDN location.
What Still Remains Wrong
- Traffic still flows through your infrastructure first
- Users must reach your proxy before getting any CDN benefits
- Adds unnecessary latency: User → Your Proxy → CDN → Backend
- The CDN cannot optimize routing based on actual user location
- You are duplicating what the CDN already does natively
- CDNs have hundreds of edge locations with intelligent routing
- You are building a 3-region routing layer when CDN offers hundreds of locations
- Your proxies become an expensive, manual version of CDN anycast
- CDN routing is based on proxy location, not user location
# The Problem User in Mumbai → Routes to Asia Proxy (Singapore) → CDN Singapore PoP # CDN cannot optimize: Maybe Tokyo PoP would be faster for this user # Correct Approach User in Mumbai → CloudFront routes to closest PoP (Mumbai/Chennai) → Origin # CDN intelligently selects from hundreds of locations - Cost and operational complexity
- Running multi-region proxy infrastructure is expensive
- Manual failover configuration between regions
- More moving parts = more failure modes
The Correct Multi-Region Approach
Instead of multi-region proxies, use CloudFront with native multi-region support:
CloudFront + Origin Groups (Automatic Failover):
User Anywhere → CloudFront (automatic routing to nearest PoP)
→ Primary Origin (US-East ALB)
→ Secondary Origin (EU-West ALB) [automatic failover]
Benefits:
- CloudFront handles global routing automatically
- Origin Groups provide automatic failover between regions
- No proxy infrastructure to manage
- Users always route to their nearest edge location
- Lower latency, lower cost, higher availability
The fundamental issue is not single vs. multiple regions—it is placing the CDN after your infrastructure instead of in front of it. Multi-region proxies add cost and complexity while still defeating the CDN’s core purpose.
Key Takeaways
The anti-pattern is universal: Placing a CDN after your reverse proxy (whether it is nginx, HAProxy, ALB or API Gateway) defeats the CDN’s distributed architecture and creates a hidden single point of failure.
In AWS specifically: CloudFront must be user-facing to work correctly. Choose ElastiCache for internal caching needs, CloudFront in front of ALB for global content delivery or Lambda@Edge for edge computing.
The fix is architectural: This is not about tweaking configurations—it is about placing components in the right order. CDNs belong between users and your infrastructure, not between your infrastructure components.
Published on:
Learn more