Dataverse Elastic Tables Deep Dive Tutorial
Dataverse Elastic Tables Deep Dive Tutorial
Intro
Said to be the "Super Heros" of the information world, that they're super fast and can store lots of information and that they're a game changer for storing massive loads of data.
I went to undercover what's behind the scenes of this Elastic Tables feature and check if the rumours are fake or not!
Principles and Architecture
Microsoft use Cosmos DB instead of azure SQL to store data, meaning they have a special column called Partition ID that organizes information in a "folders" like structure.
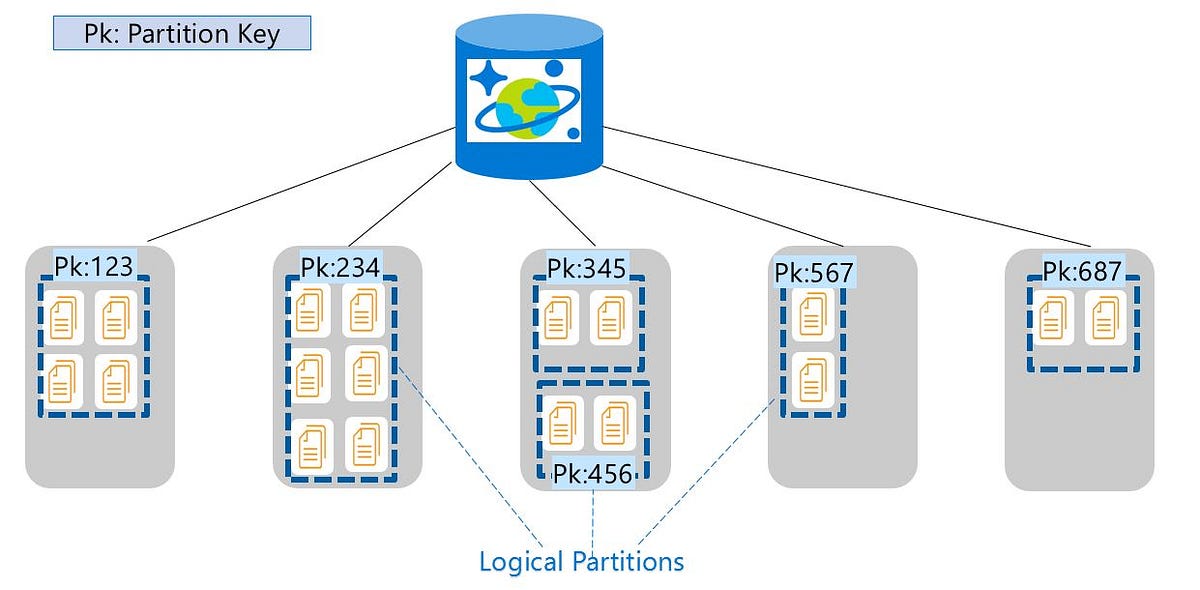
Partitioning and Horizontal Scaling:
- Elastic tables use Azure Cosmos DB partitioning to scale individual tables
- Each elastic table contains a system-defined Partition Id column
- Rows are divided into distinct subsets (logical partitions) based on the value of the partitionid column, like storing rows per in folder by its partitionId
- Choosing a consistent partitioning strategy is crucial for optimal performance
Unique References and Partitioning:
- Unique references for elastic tables combine the primary key and the partitionid value
- There is no limit on the number of logical partitions
- If you don’t set a partitionid value, it remains null
- Custom partitionid values allow multiple records with the same primary key but different partition IDs
- PartitionId cannot be changed after creating a row
Consistency level
Elastic table supports strong consistency during a logical session. A logical session is a connection between a client and Dataverse. When a client performs a write operation on an elastic table, it receives a session token that uniquely identifies the logical session. To have strong consistency, you must maintain the logical session context by including the session token with all subsequent requests.
Session tokens ensure that all the read operations that are performed during the same logical session context return the most recent write that was made during that logical session. In other words, session tokens ensure that reads always honor the read-your-writes and write-follows-reads guarantees during a logical session. If a different logical session performs a write operation, other logical sessions might not immediately detect those changes.
Transactional behavior
For example, you have a synchronous plug-in step that is registered on the PostOperation stage of the Create message on an elastic table. In this case, an error that occurs in the plug-in does not roll back the record that is created in Dataverse. You should always avoid intentionally canceling any operation by throwing InvalidPluginExecutionException in the PreOperation or PostOperation synchronous stage. If the error is thrown after the Main operation, the request returns an error, but the data operation succeeds. Any write operations that are started in the PreOperation stage succeed.
However, you should always apply validation rules in a plug-in that is registered for the PreValidation synchronous stage. Validation is the purpose of this stage. Even when you use elastic tables, the request returns an error, and the data operation won't begin.
Expire data by using Time to live
Dataverse automatically includes a Time to live integer column with elastic tables. This column has the schema name TTLInSeconds and the logical name ttlinseconds.
When a value is set in this column, it defines the amount of time, in seconds, before the row expires and is automatically deleted from database. If no value is set, the record persists indefinitely, just like standard tables.
Flexible schema with JSON columns
Elastic tables enable you to store and query data with varying structures, without the need for predefined schemas or migrations. There's no need to write custom code to map the imported data into a fixed schema. More information: Developer guide: Query JSON columns in elastic tables Elastic tables enable you to store and query data with varying structures, without the need for predefined schemas or migrations. There's no need to write custom code to map the imported data into a fixed schema. More information: Developer guide: Query JSON columns in elastic tables.
Limitations
Table features currently not supported with elastic tables:
- Business rules
- Charts
- Business process flows
- One Dataverse connector for Power BI
- Many-to-many (N:N) relationships to standard tables
- Alternate key
- Duplicate detection
- Calculated and rollup columns
- Currency columns
- Column comparison in queries
- Table sharing
- Composite indexes
- Cascade operations: Delete, Reparent, Assign, Share, Unshare
- Ordering on lookup columns
- Aggregate queries:
- Distinct value of attribute1 while orderby on attribute2 value
- Pagination when having multiple distincts
- Distinct with multiple order by
- Order by and group by together
- Group by on link entity (left outer join)
- Distinct on user owned tables
- Table connections
- Access teams
- Queues
- Attachment
Currently, you can't add the following types of columns:
- Money (MoneyAttributeMetadata)
- MultiSelectPicklist (MultiSelectPicklistAttributeMetadata)
- State (StateAttributeMetadata)
- Status (StatusAttributeMetadata)
- Image (ImageAttributeMetadata)
- Calculated, Rollup, or Formula Columns
- Currency
- Lookup based on the Customer option
Relationships with elastic tables:
- Doesn't support creating many-to-many relationships
- One-to-many relationships are supported for elastic tables with the following limitations:
- Cascading isn't supported. Cascading behavior must be set to Cascade.None when the relationship is created
- Formatted values for lookup columns aren't returned when the following conditions are true
- The table that is retrieved is a standard table, and the lookup refers to an elastic table
- You're using a custom elastic table partitionid value. In other words, the partitionid value is set to something other than the default value (null).
- Elastic tables support one-to-many relationships, and related rows can be retrieved when a record is retrieved. Related records can't be included in a query
Also:
- Duplicate detection or adding activities aren't supported
- Return related rows in a query
- Elastic tables don't currently support returning related rows when a query is run. If you try to return related rows
- Deep insert is not supported with elastic tables. Each related record needs to be created independently
- Elastic tables don't support multi-record transactions
- Elastic tables also don't support grouping requests in a single database transaction that uses the SDK ExecuteTransactionRequest class or in a Web API $batch operation changeset. Currently, these operations succeed but aren't atomic
Hands-on
After the theoretical side of the elastic tables let's demystify them by putting our hands-on creating and playing with some of the standard features.
Creating an elastic table
On the Power Apps maker portal inside your solution create a new table and then select the type elastic.
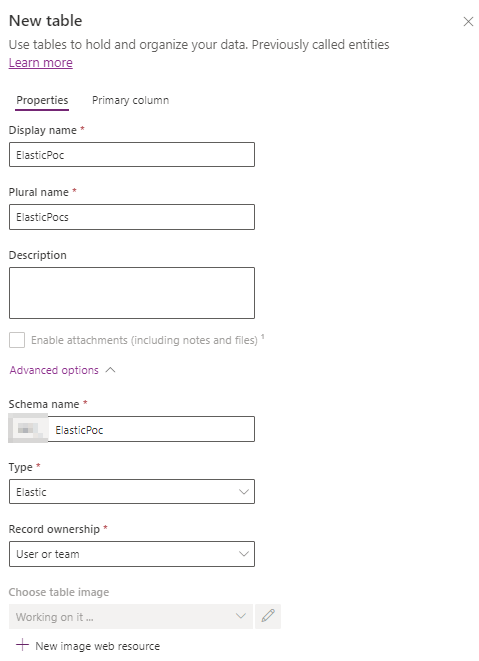
In the table properties as shown in the image below we can check that some of the default table features aren't available for the elastic tables (creating activities, duplicate detection rules, connection, SharePoint document management, ...)
Exploring the elastic table Columns
Creating a new column on the elastic table has pretty much the same look & feel except for the missing options in the data type choice list (Currency, Formula, Customer Lookup).
A new option arises with the elastic tables within the data type single line of text we can now chose a new format, the JSON.
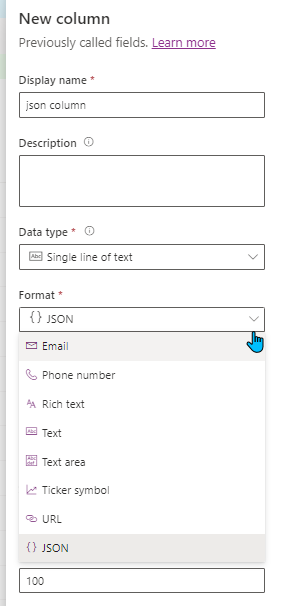
We now have our table created and let's see the aspect of some of the default columns present in it with our JSON Column in the image below.
Two new columns are present:
- Partition ID: as explained above it defines the logical compartiment to store the record, it cannot be changed after the record creation
- Time to Live: measured in seconds and determine the time the record will remain in the table

Considerations around the partitionid column that should meet these criteria:
- The values in it don't change. After a row is created that has a partitionid value, you can't change it
- It has a high cardinality value. In other words, the property should have a wide range of possible values. Each logical partition can store 20 gigabytes (GB) of data. Therefore, by choosing a partitionid value that has a wide range of possible values, you ensure that the table can scale without reaching limits for any specific logical partition
- It spreads data as evenly as possible among all logical partitions
- No values are larger than 1,024 bytes
- No values contain slashes (/), angle brackets (<, >), asterisks (*), percent signs (%), ampersands (&), colons (:), backslashes (\), question marks (?), or plus signs (+). These characters aren't supported for alternate keys
If a partitionid value isn't specified for a row, Dataverse uses the primary key value as the default partitionid value. For write-heavy tables of any size, or for cases where rows are mostly retrieved by using the primary key, the primary key is a great choice for the partitionid column.
When querying the JSON column:
Using the the default filter in the table view only uses standard text filtering options so here we will only be able to check for the presence of strings inside the JSON but no more than this.
However great news comes with You can use the ExecuteCosmosSQLQuery message that enables to run any Cosmos SQL query directly against your elastic table and filter rows based on properties inside JSON.
So let's try it in our created table and column !
Using the WebAPI we create the following http request, also available using the Dataverse SDK for .NET:
/api/data/v9.2/ExecuteCosmosSqlQuery(
QueryText=@p1,
EntityLogicalName=@p2,
QueryParameters=@p3)?
@p1='select c.props.sc_name as name, c.props.sc_jsoncolumn as json, c.props.sc_jsoncolumn.age as age
from c where c.props.sc_jsoncolumn.car=@car and c.props.sc_jsoncolumn.age >= @age'
&@p2='sc_elasticpoc'
&@p3={'Keys':['@car', '@age'],'Values':[{'Type':'System.String','Value':'Mustang'}
, {'Type':'System.Int32','Value': '20'}]}
where "sc_elasticpoc" is our table, the "sc_jsoncolumn" is our JSON column and c.props is the prefix on the schema name of the columns. In this prefix, c is an alias or shorthand notation for the elastic table that is being queried.
And the result is:
{
"@odata.context":"https://orgf9a090a4.crm17.dynamics.com/api/data/v9.2/$metadata#expando/$entity"
,"@odata.type":"#Microsoft.Dynamics.CRM.expando","PagingCookie":"","HasMore":false,"[email protected]":"#Collection(Microsoft.Dynamics.CRM.expando)"
,"Result":
[{"@odata.type":"#Microsoft.Dynamics.CRM.expando","name":"elastic 2","age":20
,"json": {"@odata.type":"#Microsoft.Dynamics.CRM.expando","name":"Paul","age":20,"car":"Mustang"}}]
}
Final considerations between Elastic and Standard tables:
Performance:
As some announcements might let us think that elastic tables offer super performance over standard tables there are some studies that shows that's not quite the reality like in the Piotr Gaszewski blog (https://piotrgaszewski.hashnode.dev/dataverse-elastic-tables) that states:
-
Standard Create, Update, Delete operations: takes the same or a little bit more time to execute in elastic tables than in standard ones
-
Multiple Create, Update, Delete operations: takes significantly less time to execute in elastic tables than in standard ones (1/2 to 1/10)
-
Retrieve data operations: takes 2 to 3 times longer in elastic tables than in standard ones
So elastic tables offers significantly less performance execution times when using single atomic operation, however when working with multiple records on the same request it offers some advantages.
Service API Limits:
As per MS, Elastic Tables are still exposed to the Dataverse API throttling limits and bulk operation messages should be used to increase the throughput for high volume operations.
Is security model user compatible:
MS says yes that Elastic tables adhere to the Dataverse security model using
- an User or Organisation level ownership
- field level security
And yes audit is also available for elastic tables!
Conclusion:
Elastic tables enlarges the table types offer in dataverse, but it's to take with caution in my opinion because these pretty tables aren't the way to go to standard development in a relation database context, since table lookups aren't available ootb and since many other table features aren't also available which reduces a lot the scope of action of these tables.
Regarding performance finally they're also not the way to go if you search for increasing CRUD performances, except using multiple CRUD operations.
So my final take on the elastic tables would be for storing large datasets of data and mainly for IoT data that would managed by a service layer capable of using multiple CRUD operations and then consuming the data on a business intelligence scheme (as an example only).
Dataverse Elastic Tables Deep Dive Tutorial
Published on:
Learn more